Learn about some exciting research on language learning from David Abugaber, a PhD candidate in Dr. Kara Morgan-Short’s Cognition of Second Language Acquisition laboratory. You can find out more about him and his research at www.davidabugaber.com or by emailing dabuga2@uic.edu.
There’s a classic joke about second language acquisition that goes something like this: an English learner on vacation in the USA gets in a terrible traffic accident. The paramedics rush to him at the scene of the crash, yelling out “Are you OK?!” Bloodied and half-conscious at the scene of the crash, the English learner stammers, “I’m… fine… thank… you… and… you?”
This joke gets at something that most classroom language learners have probably run into: the massive disconnect between “grammar as access to meaning” vs. “grammar as muscle memory.” However, traditional frameworks from linguistic theory – whether they conceive of language as hierarchical syntactic trees with discrete branching nodes or as construction-style templates with embedded meaning such as “[VERB] the [TIME PERIOD] away” – don’t distinguish between these two styles of processing. If theoretical linguists are serious about relating their field of study to language learners’ lived experiences (rather than waving their hands and saying that manifestations of language in the real world fall under the category of “performance,” outside of their abstract idealized domain of “competence”), then they should stop ignoring the fact that grammar can be used in real life – and even used successfully – without necessarily engaging meaning.
This distinction between meaning-based vs. meaning-agnostic grammar processing can be examined by combining mathematical models from cognitive psychology with a classic artificial language paradigm that involves a covert rule wherein the pseudowords “gi” and “ul” tend to co-occur with nouns for living things whereas “ro” and “ne” tend to co-occur with non-living things. The trial structure for this experiment paradigm is shown below:

Notice that there’s two possible ways to apply the covert grammatical rule in this experiment: either by seeing “gi” and immediately activating the mental concept of “living” (thus, “grammar as meaning”), or by seeing “gi” and anticipating a button press for the answer choice “living,” without actually thinking of a living/non-living distinction (thus, “grammar as muscle memory”). These two kinds of processing can be pulled apart using mathematical models that describe cognition in two-choice reaction time tasks decisions by differentiating between processes tied to “evidence accumulation” vs. time spent in non-decision-related processes (e.g., tied to non-cognitive factors like motor speed or speed of low-level perception). One such model, called the drift-diffusion model, is illustrated below:
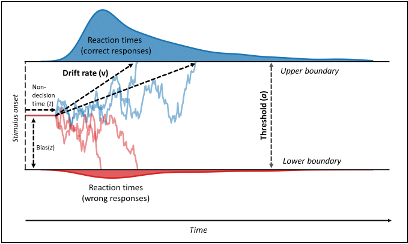
In our results, participants who consciously noticed the hidden grammar rule showed the first kind of effect: their drift-diffusion modeling results showed that bias in evidence accumulation at the start of each trial (denoted z in the figure above) was affected for trials that violated the grammatical rule. By contrast, participants who did not consciously notice the rule showed the second kind of effect: they learned the rule subconsciously (as indicated by having overall faster reaction times to rule-following vs. rule-violating trials), but their rule learning was manifested as changes to non-decision times (denoted t in the figure above) such that their responses were affected because of factors outside of evidence accumulation process (maybe their index fingers were too eager to hover above the predicted answer key?). This suggests that they had become subconsciously attuned to recurring predictable button-press patterns in the experiment. These results present an interesting case study for second language educators about how successful task performance does not always require actual engagement with meaning.
We are currently collecting data to determine whether subconscious grammar learning can occur even when button presses in the experiment aren’t predictable. For now, though, my challenge to linguists out there is: is meaning-based grammar use necessarily “better”? Doesn’t automatizing language use lead to faster and less metabolically-costly processing? As an L2 learner, I can think of so many times when having a handy memorized phrase in my holster, ready to deploy “out of the box” with “no assembly required,” took me a lot farther than a hyper-abstract metalinguistic rule that is more generalizable but kills the flow of conversation, if you have to stop and mentally apply it mid-sentence (“If there is both a direct object clitic and an indirect object clitic, then the first clitic gets replaced with se…”). To illustrate this more tangibly for any Spanish teacher out there: hasn’t this catchy earworm of a song done much more for teaching learners to say “I like ___ “, much more than a boring grammar explanation ever did? Manu Chao – Me gustas tú – YouTube